DB

k6 test
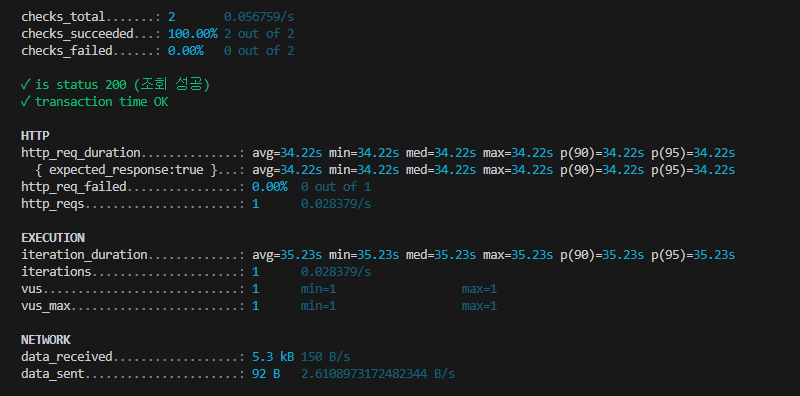
겁나느림. 뭔 32초나걸림..
5.3kb인걸 긁어오는게 느리다는것은 데이터자체가 무겁지는 않다는것
코드 분석
/**
* 1. 발주 목록 조회
* - 모든 발주 목록을 조회한다.
*/
@GetMapping
public ResponseEntity<Page<PurchaseSummaryResponseDto>> findPurchases(
@ModelAttribute TradeSearchCondition cond,
Pageable pageable
) {
Page<PurchaseSummaryResponseDto> response = purchaseService.findPurchases(cond, pageable);
return ResponseEntity.ok(response);
}Page<PurchaseSummaryResponseDto> findPurchases(TradeSearchCondition cond, Pageable pageable);
// 발주 목록 조회
@Override
@Transactional(readOnly = true)
public Page<PurchaseSummaryResponseDto> findPurchases(TradeSearchCondition cond, Pageable pageable) {
if (pageable == null) {
pageable = PageRequest.of(0, 10, Sort.by(Sort.Direction.DESC, "createdAt"));
}
return purchaseRepository.search(cond, pageable).map(PurchaseSummaryResponseDto::fromEntity);
}
페이지 네이션 사용함
@Override
public Page<Purchase> search(TradeSearchCondition cond, Pageable pageable) {
// 조건 매핑
String searchText = cond.getSearchText();
List<String> statusStrings = cond.getStatuses();
Long vendorId = cond.getVendorId();
// 목록
List<Purchase> content = queryFactory
.selectFrom(purchase)
.leftJoin(purchase.user, QUser.user).fetchJoin()
.leftJoin(purchase.supplier, QSupplier.supplier).fetchJoin()
.where(
statusIn(statusStrings),
searchTextContains(searchText),
vendorIdEq(vendorId),
createdAtAfterOrEq(cond.getFromDate()),
createdAtBeforeOrEq(cond.getToDate())
)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(purchase.createdAt.desc())
.fetch();
// total (count 쿼리에는 JOIN 불필요, WHERE 절만 동일하게 적용)
Long total = queryFactory
.select(purchase.count())
.from(purchase)
.where(
statusIn(statusStrings),
searchTextContains(searchText),
vendorIdEq(vendorId),
createdAtAfterOrEq(cond.getFromDate()),
createdAtBeforeOrEq(cond.getToDate())
)
.fetchOne();
return new PageImpl<>(content, pageable, total != null ? total : 0);
}
문제 1. 시작 종료일이 없으면 모두 긁어옴.
수정 1. 확인해보니 조건에 기본값이 없음.
결과 1. 여전히 느림.
여기서 DB explain

문제 2. rows 풀스캔. 외래키 넣은줄알았는데 없었음. 추가로 외래키 제약조건은 안쓰기로해서 빼놓음
수정 2. 외래키로 취급할 인덱스 추가. (외래키는 사용X 삭제 어려움 존재)
결과 2. DB row풀스캔 제거

문제3. 그럼뭐함 supplier_id나 user_id가 없는경우 여전한 풀스캔
수정3. 인덱스 추가
결과3. db 풀스캔 제거

결과 여전함
코드 다시 확인했는데 N+1 문제
purchase.getPurchaseDetails()를 호출할 때마다 추가 쿼리 발생+ 인덱스문제
public static PurchaseSummaryResponseDto fromEntity(Purchase purchase) {
// 1. 초기 총액을 BigDecimal(0)으로 설정
BigDecimal totalAmount = purchase.getPurchaseDetails().stream()
.map(pd -> {
// 2. 각 상세 항목별 금액 계산: (수량 * 단가)
// 수량(Integer)을 BigDecimal로 변환하여 단가(BigDecimal)와 곱합니다.
BigDecimal itemQty = new BigDecimal(pd.getOrderQty());
BigDecimal itemPrice = pd.getUnitPrice(); // getUnitPrice가 BigDecimal이라고 가정
// 항목별 금액 = 수량 * 단가 (BigDecimal 연산)
return itemQty.multiply(itemPrice);
})
// 3. 모든 항목별 금액을 누적 합산 (reduce)
.reduce(BigDecimal.ZERO, BigDecimal::add);
return PurchaseSummaryResponseDto.builder()
.purchaseId(purchase.getPurchaseId())
.supplierName(purchase.getSupplier().getSupplierName())
.requesterName(purchase.getUser().getName())
.poNo(purchase.getPoNo())
.totalQty(purchase.getPurchaseDetails().size())
.totalAmount(totalAmount)
.orderType(purchase.getOrderType())
.status(purchase.getOrderStatus())
.requestedAt(purchase.getCreatedAt())
.build();
}
Detail에도 index추가 이후 절감 완료

늘려서 TEST
vus 100 intreations:100

N+1문제 수정
Fetch Join이 좋은 경우:
1. 일대일 관계 (User ↔ Profile)
2. 다대일 관계 (Purchase → Supplier)
3. 페이징 없는 경우
4. 컬렉션이 작은 경우 (1~2개 정도)
Batch Fetching이 좋은 경우:
1. 일대다 관계 (Purchase → PurchaseDetails) ← 우리 상황
2. 페이징 필요
3. 컬렉션이 큰 경우
페이징 필요하므로 패치 배칭 사용
수정후
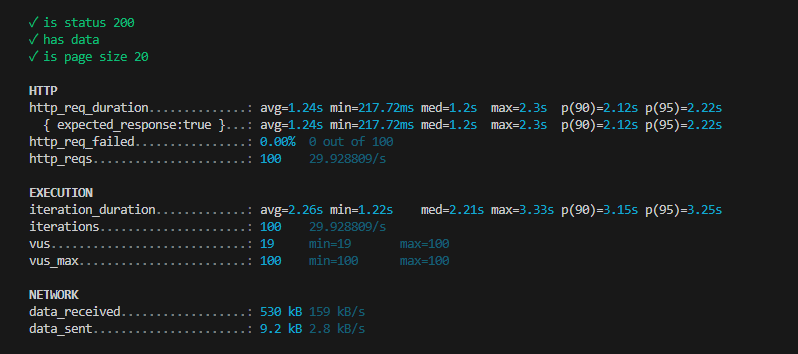
큰 차이가 없다. 왜 속도가 안줄었지에 대한 내생각.
N+1은 N이 클수록 호출되는 쿼리가 많아진다. 지금 내 코드에서는 10개로 제한되어있다. 이렇기 때문에 N+1을 수정해도 N값이 10이니 큰 차이가 없다.
여기까지 정리
1. 인덱스 없어서 80만개 풀스캔 + N+1로 엄청 오래걸림.
2. 그래서 purchase Detail과 purchase에 쿼리기준으로 인덱스 추가함.
3. 속도 정상화됨
더 많은 사람을 수용하고싶다.
1. 내 PC에 최대한 쓸 수 있는 리소스 만큼 가져다 쓸때 어느정도일까 본다.
2. 그 리소스를 참고한다.
3. 적정한걸찾는다.
쓰레드풀과 트랜잭션풀을 찾아보자.
// 테스트 구성 설정
export const options = {
stages: [
{ duration: '30s', target: 100 }, // 30초 동안 사용자를 100명까지 서서히 늘림 (Warm-up)
{ duration: '1m', target: 500 }, // 1분 동안 500명 부하 유지 (안정성 테스트)
{ duration: '30s', target: 1000 }, // 다시 30초 동안 1000명으로 급증 (한계 테스트)
{ duration: '30s', target: 0 }, // 부하 종료 및 자원 회수 확인
],
};
쓰레드 풀 기본값에서 결과

수정
쓰레드풀
| 설정 항목 | 기본값 (Spring Boot 3.x) | 현재 설정값 | 의미 |
| max (threads) | 200 | 600 | 서버가 동시에 처리할 수 있는 최대 일꾼(쓰레드) 수 |
| min-spare | 10 | 10 | 요청이 없어도 항상 대기 중인 최소 일꾼 수 |
| max-connections | 8192 | 12000 | 서버가 동시에 유지할 수 있는 최대 연결(Socket) 수 |
| accept-count | 100 | 200 | 쓰레드가 꽉 찼을 때 대기 큐(Queue)의 크기 |
커넥션
| 설정 항목 | 기본값 (Default) | 현재 설정값 | 의미 |
| maximum-pool-size | 10 | 100 | 풀에 유지할 최대 커넥션 수 |
| minimum-idle | 10 (max와 동일) | 20 | 풀에서 유지할 최소 유휴 커넥션 수 |
| idle-timeout | 600000 (10분) | 30000 (30초) | 커넥션이 놀고 있을 때 폐기하기까지 시간 |
| connection-timeout | 30000 (30초) | 20000 (20초) | 커넥션을 얻기 위해 대기하는 최대 시간 |
| max-lifetime | 1800000 (30분) | 1800000 (30분) | 커넥션의 최대 생존 시간 (보통 기본값 권장) |
결과
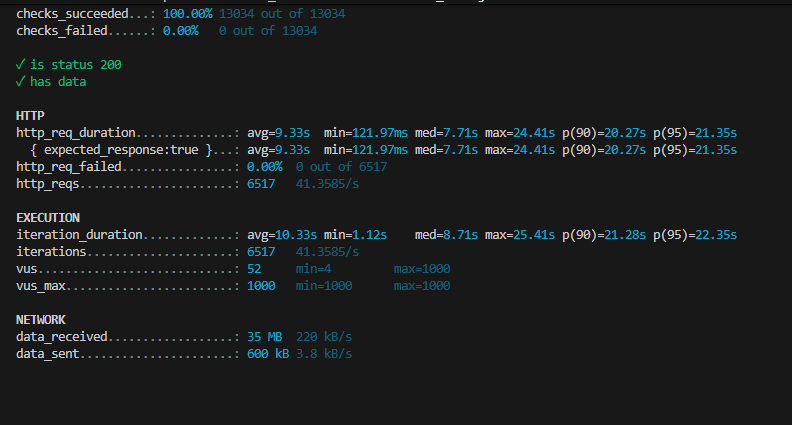
여기서 한발 더 나아가면
유저 1명이라도 더 늘리는 방법이 뭘까 생각했을때
1. 유저 1명이라도 빨리 데이터를 줄 수 있게한다.
i/o를 짱많이하면 커넥션 풀이 큰의미가 없음. 캐시 도입 급함.
그래서 레디스 쓰려는데 로컬캐시도 들어봤으니 써보자생각했음.
근데 이 둘의 차이점이 뭔데 어떨때 서야하는지 구분필요
| 구분 | 로컬 캐시 (Caffeine, Ehcache) | 레디스 캐시 (Redis, Memcached) |
| 저장 위치 | 애플리케이션 서버의 RAM(Heap 메모리) | 애플리케이션 외부의 별도 서버 |
| 속도 | 매우 빠름 (네트워크 지연 없음) | 빠름 (네트워크 통신 발생) |
| 데이터 공유 | 해당 서버 내부에서만 공유 가능 | 모든 서버 인스턴스가 공유 가능 |
| 데이터 일관성 | 서버가 여러 대면 데이터가 다를 수 있음 | 중앙 관리로 데이터 일관성 유지 유리 |
| 용량 제한 | 서버 메모리(Heap) 크기에 의존 | 외부 서버 자원에 따라 확장 가능 |
실무에서는 이 두 가지를 혼합해서 사용하는 2계층 캐시 전략을 많이 사용합니다.
- L1 캐시 (로컬): 가장 자주 접근하고 변경이 적은 데이터를 1차로 조회 (네트워크 비용 0).
- L2 캐시 (Redis): L1에 없으면 Redis에서 조회.
- DB 조회: Redis에도 없으면 최종적으로 DB에 접근.
지만 나는 서버pc가 2대없다. 그럼 레디스로 통일해도 되지않냐 혹은 로컬캐시로 통일하면 되는거아니냐 생각했는데 로컬캐시는 was에서 직접 내뱉으니까 데이터가 최신화되지 않을 수 있다. 만약 was가 2개로 늘어나면 ? 코드 다시 캐시 구조를 수정해야된다. 그러므로 L1 L2를 나누는게 맞다.
로컬 캐시 도입후 쓰레드풀 그대로 + 커넥션풀 그대로 기준
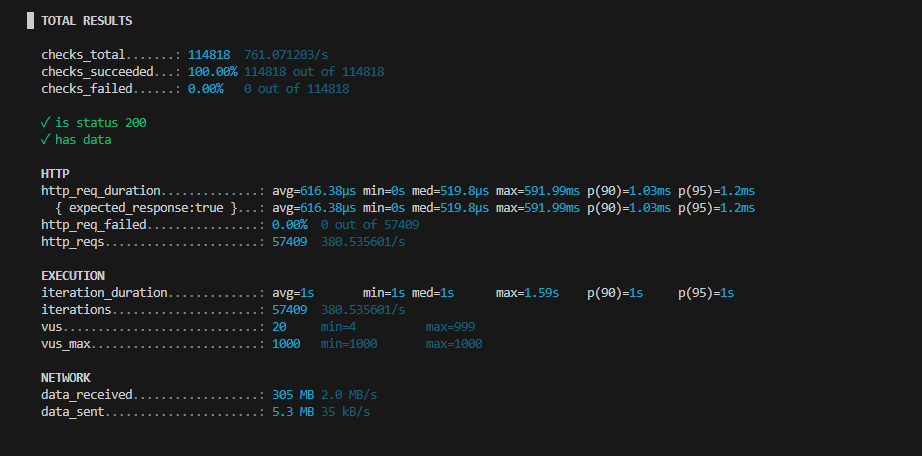
진짜 빨라졌댜. redis보다 차원이 다르게 빠르다.
이제 더 수용능력을 늘려보자.
최적화 진행과정은
1. 캐시를 도입하는게 효과 체감이 제일된다.
2. 이후에 미어터지는건 스레드풀과 커넥션풀을 조절한다.
3. 만약 여분의 서버가있다면 늘려서 분산시스템을 구축하는게 좋다.
쓰레드풀 커넥션풀 늘린다고해서 무조건 빨라지는게 아닌이유.
- DB 서버의 CPU/디스크 경합:
- 10명이 동시에 쿼리를 날릴 때 DB CPU가 100%였다면, 100명이 동시에 날린다고 해서 DB가 10배 빨라지지 않습니다. 오히려 100명이 CPU 하나를 나눠 쓰느라 개별 쿼리 속도는 10배 더 느려집니다.
- 결과적으로 **[대기 줄은 짧아졌지만, 한 명당 처리 시간이 10배 늘어남]**이 상쇄되어 전체 응답 시간은 21초로 똑같게 나오는 것입니다.
- 데이터의 물리적 한계:
- 85만 건을 뒤지는 작업이 디스크 I/O를 발생시킨다면, 커넥션 100개가 동시에 같은 디스크 섹터를 읽으려고 경쟁합니다. 디스크 헤드가 움직이는 속도는 물리적으로 정해져 있기 때문에 통로가 넓어져도 데이터가 나오는 속도는 똑같습니다.
1. 커넥션 풀을 늘려야 하는 결정적 상황
- Wait Time 폭증: 쿼리 실행 시간(Execution Time)은 짧은데, 커넥션을 얻기 위해 기다리는 시간(Connection Acquisition Time)이 길 때.
- 낮은 DB 부하: 서버 응답은 느린데, 정작 DB 서버의 CPU 사용률은 10~30%대로 한가할 때.
- Time-out 에러: Connection is not available, request timed out 에러가 로그에 찍힐 때.
2. 이를 확인하기 위한 테스트 케이스 (실전)
Case A: "입구 컷" 현상 확인 (현재 설정 vs 풀 증설)
로직은 아주 가벼운데(예: SELECT 1), 동시 접속자가 많아서 처리가 안 되는 상황을 가정합니다.
- 테스트 로직: DB 인덱스가 잘 타서 0.01s 내외로 끝나는 아주 가벼운 조회 API.
- 부하 설정: 쓰레드 풀 500개 / 가상 유저(VUs) 1,000명.
- 실험 방법:
- maximum-pool-size: 10으로 설정 후 k6 실행.
- maximum-pool-size: 100으로 설정 후 k6 실행.
- 기대 결과: 이때는 $p(95)$ 응답 속도가 수 초에서 밀리초(ms) 단위로 드라마틱하게 개선됩니다. 왜냐하면 DB가 빨리빨리 처리해주는데, 커넥션 10개가 모자라 줄을 서있던 것이 100개로 늘어나며 병목이 뚫리기 때문입니다.
Case B: "회전율" 테스트 (짧은 쿼리 다수 발생)
하나의 요청이 여러 번의 짧은 쿼리를 날리는 경우입니다.
- 테스트 로직: 한 번의 API 호출에서 DB를 5~10번 찔러야 하는 복잡한 비즈니스 로직.
- 실험 방법: 위와 동일하게 풀 개수를 조절하며 테스트.
- 분석 포인트: http_req_waiting 시간이 줄어드는지 확인. 만약 풀을 늘렸을 때 이 수치가 줄어든다면, 그동안은 쓰레드가 커넥션을 잡기 위해 멍하니 기다렸다는 뜻입니다.
'Archive(완료된 내용) > 포트폴리오 강화' 카테고리의 다른 글
| 게임 안 NPC와 플레이어가 인스타그램 UI에서 댓글로 상호작용 구현 (0) | 2026.03.05 |
|---|---|
| [order101] 최적화 및 시나리오 - 12일차 (0) | 2026.02.05 |
| [stock101] 성능 개선 해보기 - 11일차 (0) | 2026.02.03 |
| [stock101] Redis 캐싱 적용하기 - 11일차 (1) | 2026.02.03 |
| [Stock101] gemini api를 쓰자. - 10일차 (0) | 2026.02.03 |