성능 및 부하 test는 여러 툴이있다. jmeter는 gui가있어서 편하다고하는데 결과나 이런건 자세히 볼 수 있어 좋으나 내가 하고자 하는거에 비해 큰 볼륨같이 느껴진다.
이번에는 k6라는걸 간단하게 빠르게 써볼 수 있다기에 써보려고한다.
코드는 AI친구에게 물어보면 잘짜준다.
간단하게 공부한건 아래같이 의미파악 정도
vus 동시에 테스트 진행할 가상 사용자수
duration 테스트 지속 시간
interactions 총 요청 수 (vus * duration 초)
stage 단계 조절
threshold 성능 기준 설정
k6 run test.js 명령어로 실행
http_reqs : tps확인 초당 몇건 처리
http_req_duration (처리 시간):
그래서 내가 설계한건 유저 시나리오 그대로 test해보려고한다.
메인 페이지에서는 전체 종목을 1회 호출한다. 이후 캐싱해서 사용한다. 코스피는 신규 상장 제외하고 그대로니까 캐싱처리했다.
-> ai리포트 목록을 호출한다. -> 로그인 -> 주식 deatil 페이지를 조회한다. -> 업데이트 유무에따라 최신화한다 -> dart공시 문서 목록을 호출한다 -> 선택한 주식에 맞게 리포트도 상세 조회한다
k6를 1차 조회한거 점진적 10초간 100명증가 이후 100명이 10초간 test 이후 OFF

k6를 2차 조회한거 점진적 10초간 500명증가 이후 500명이 10초간 test 이후 OFF
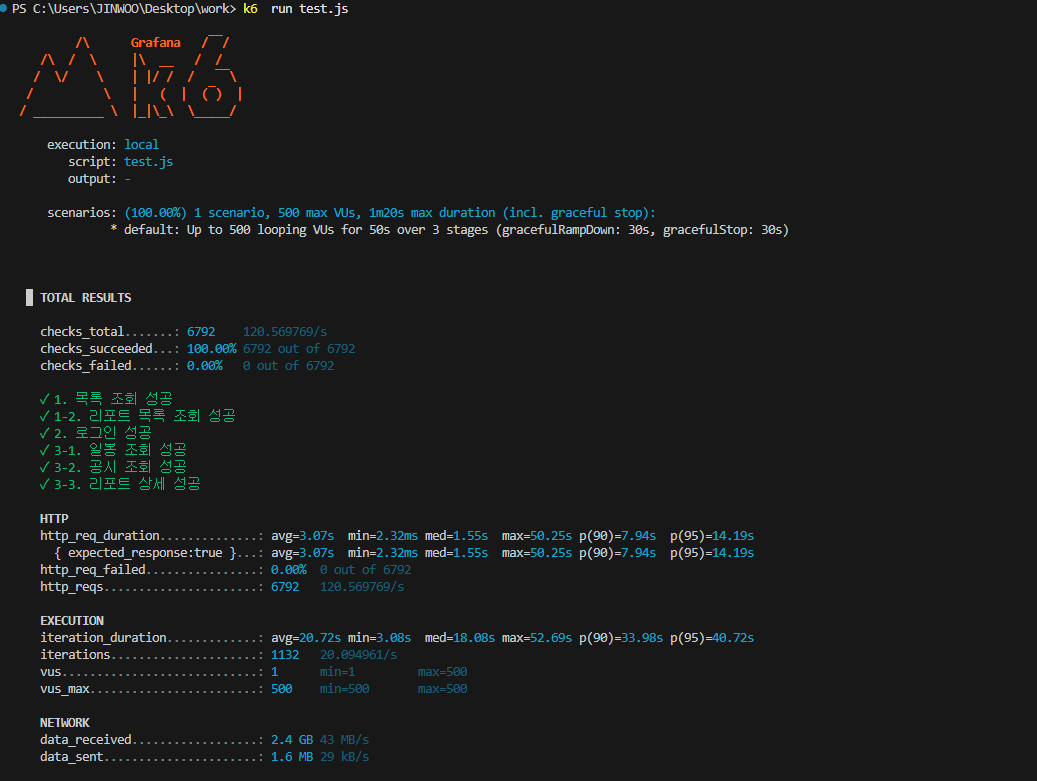
500명일때 평균 3초씩이나 걸리는걸 볼수있다. 5%유저는 14초나 기다려야했고 어떤 유저는 50초씩이나기다렸다.
1. 응답 시간의 처참한 붕괴 (Latency)
가장 심각한 지표는 http_req_duration입니다.
- 평균 응답 시간 (avg): 3.07초 (100명 때 0.38초에서 8배 증가)
- 상위 95% 응답 시간 (p95): 14.19초
- 최대 응답 시간 (max): 50.25초
- 분석: 어떤 유저는 일봉 조회 하나 하려고 50초를 기다렸습니다. 실제 서비스였다면 사용자는 이미 창을 닫았을 것이고, 브라우저는 '응답 없음'을 띄웠을 시간입니다.
2. TPS의 한계 (Throughput)
- TPS: 약 120 req/s
- 100명일 때 110 TPS였는데, 유저를 500명으로 5배 늘렸음에도 TPS는 겨우 10 늘어났습니다.
- 의미: 서버의 처리 능력이 이미 계단 끝까지 도달했다는 뜻입니다. 유저를 더 부어봤자 서버가 빨리 처리하지 못하니 줄만 길게 서 있는 형국입니다.
3. 처리 효율 급감
- iteration_duration (avg): 20.72초
- 한 명의 유저가 로그인하고 상세 페이지까지 보는 데 20초가 걸립니다. (이전 테스트는 4.33초)
- 서버 내부의 작업 큐(Queue)가 꽉 차서 자기 차례가 올 때까지 한참을 기다리고 있는 상태입니다.
이걸로 낼 수 있는 결과 우선 내 서비스는 약 150명정도 이용할 수 있는 페이지다.
이제 범인을 찾아봐야한다.
함수 1개씩 제거해서 test해본다.
문제 1. 데이터 received에서 43MB를 수신했다. 왜 이렇게 비싼 데이터를 보냈지?
몇번을 test해도 네트워크 최대는 43MB수준이다 그러면 나는 40MB안으로 데이터를 보낼 수 있게 압축해야 한다.
AI말대로 일단 수정해봄.
문제 원인 및 문제점
- 네트워크 대역폭 포화 (Network Bandwidth Bottleneck)
- 일봉 데이터(600일치) 및 목록 조회 API 호출 시 발생하는 응답 데이터가 압축 없이 전송됨.
- 500명 동시 접속 시 초당 약 **47 MB(376 Mbps)**의 트래픽이 발생하여 홈서버의 업로드 대역폭 한계에 도달.
- 서버 자원 관리 한계 (Resource Exhaustion)
- k6 테스트가 Nginx를 거치지 않고 백엔드(8080 포트)에 직접 요청을 보내면서, 서버의 CPU 및 쓰레드가 대량의 Raw 데이터를 처리하고 송출하는 데 과부하 발생.
- 이로 인해 응답 시간이 지수적으로 상승하여 최대 50초 이상의 지연(Latency) 발생.
해결 과정
- 리버스 프록시(Reverse Proxy) 및 Gzip 압축 도입
- 백엔드 앞단에 Nginx를 배치하여 모든 외부 요청을 80포트로 단일화.
- gzip on 설정을 통해 application/json 등 텍스트 기반 응답 데이터를 압축 전송하도록 구성하여 네트워크 부하를 획기적으로 감소시킴.
- Nginx API 프록시 경로 설정 및 헤더 최적화
- location /api 블록을 설정하여 백엔드 서비스(stock101-backend:8080)로 요청을 중계.
- proxy_set_header X-Real-IP 등을 사용하여 백엔드 서버가 실제 클라이언트의 IP를 식별할 수 있도록 구현.
테스트 방법
- k6 부하 테스트 경로 수정
- 기존 백엔드 직접 호출(:8080) 방식에서 Nginx(:80) 경유 방식으로 BASE_URL 변경.
- 로컬 환경 기반 성능 검증
- 동일 네트워크(내부 IP) 상에서 500 VUs(Virtual Users) 규모의 부하를 발생시켜 Gzip 압축 적용 전/후의 data_received 수치 비교.
- 보안 설정 검증
- 공유기의 포트 포워딩 상태를 점검하고, Nginx의 limit_req 모듈 적용 준비 및 SSH 포트 변경을 통한 외부 공격 지점(Attack Surface) 축소 확인.
다시 test해도 문제있음
다른 방향 일단 api가 무거운지 다시 확인
const reportRes = http.get(`${BASE_URL}/api/disclosure/reports/recent`);

목록 조회가 무거운건 사실.
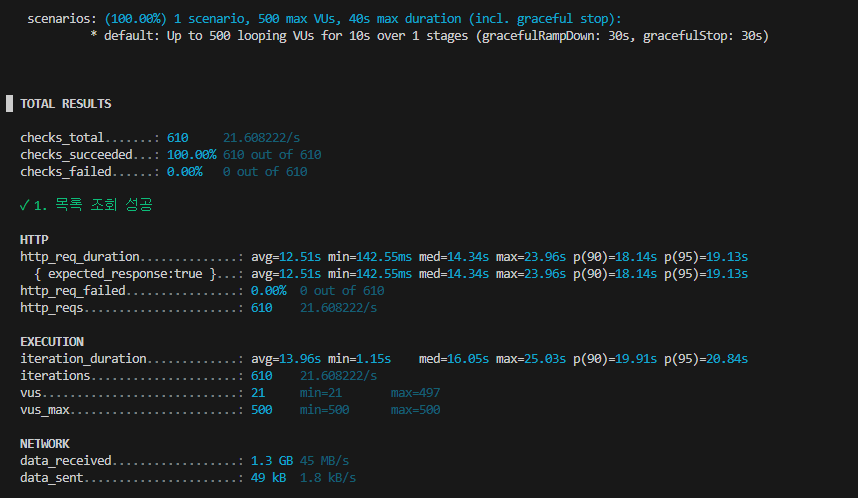
차이 확인한건
1. DB에 데이터가 많긴하다. 약 5천개의 모든 종목임
속도가 느린거
1. stock에 필요없는 데이터 dto stock을 호출하는건 괜찮은데 front에서 필요없는것도 주지마세요. 데이터를 줄였다 어트리뷰트들 정리하고 전체목록에서 필요한 정보만 빼왔다.
2. 확인해보니까 캐싱안하고 일일히 모든 데이터를 조회함 -> 캐싱 필요 캐싱 해도 되는이유 1. 모든 stock 업데이트는 신규상장이나 폐지와같이 정해진 시간에만 값이 변하고 그외에는 변하지 않음.
1번 결과

역시 절대적인 근본 제거가 효과가 좋다.
추가로 캐싱을 적용했다.
캐싱은 엄청크게 유의미해보이지는 않았으나 저점을 수호해줬다.

목록조회는 100-> 500까지 성능개선
13.96s -> 2.67s 개선
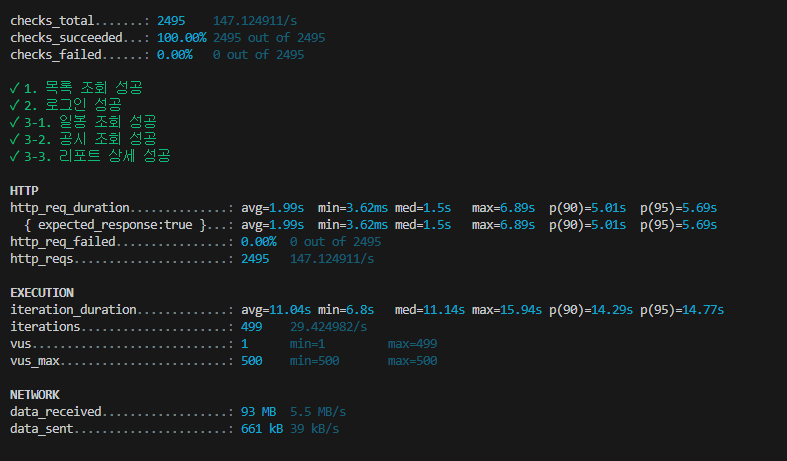
개선이 더 필요하다. 5%는 4초동안 응답이없다. 추가로 네트워크도 전송량이 많다.
시나리오 10초간 500명 test시 아래와같다.
'Archive(완료된 내용) > 포트폴리오 강화' 카테고리의 다른 글
| [order101] 주문 목록 조회 최적화 (0) | 2026.02.10 |
|---|---|
| [order101] 최적화 및 시나리오 - 12일차 (0) | 2026.02.05 |
| [stock101] Redis 캐싱 적용하기 - 11일차 (1) | 2026.02.03 |
| [Stock101] gemini api를 쓰자. - 10일차 (0) | 2026.02.03 |
| [Stock101] 프로젝트 기획 마무리 정리 - 10일차 (0) | 2026.02.03 |